
Section 6
Data Coding and Data Extraction
Last updated: September 25th 2022
For CEE Standards for conduct and reporting of data coding and extraction click here
6.1 Background
Systematic Reviews and Systematic Maps are based on data that are extracted systematically and transparently from each eligible study using procedures that are sufficiently well documented to allow other reviewers to obtain the same data from the same studies. The term ‘data’ is used here to mean any information about (or deriving from) a study, including qualitative and quantitative data describing details of methods, location or setting, context, interventions, outcomes, and results (Higgins and Green 2011).
Data coding and data extraction refer to the process of systematically extracting relevant information from the articles included in the evidence synthesis. Data coding is the recording of relevant characteristics (meta-data) of the study such as when and where the study was conducted and by whom, as well as aspects of the study design and conduct. Data coding is undertaken in both Systematic Reviews and Systematic Maps. Data extraction refers to the recording of the results of the study (e.g. in terms of effect size means and variances or other important findings). Data extraction is undertaken in Systematic Reviews only (see 6.2 below). The precise order in which data coding, critical appraisal and data extraction are undertaken varies from one evidence synthesis to another. In our experience, there is frequently an iterative relationship between them and they are often conducted together. Therefore our advice is to read through both this Section and Section 7 before proceeding.
Coded and extracted data should be recorded on carefully designed forms and undertaken with the appropriate synthesis in mind (see Section 8). Great care should be taken to standardise and document the processes of data coding and data extraction, the details of which should be reported to increase the transparency of the process. Because each review is different, data collection forms will vary across reviews. However, there are many similarities in the types of information that are important, and forms can be adapted from one review to the next. PICO/PECO key elements can help addressing the structure and components of the data coding and extraction forms. To some extent data coding and data extraction should be guided by a priori rules described in the protocol, but the complexity of the operation means a degree of flexibility may be maintained. Sensitivity analyses can be used to investigate the impact of coding and extracting data in different ways when there is doubt about the optimum method.
6.2 Planning for data coding (Systematic Reviews and Maps) and data extraction (Systematic Reviews)
A standard data coding or extraction form or table (e.g. spreadsheet) is usually developed and pilot-tested on full-text copies of the relevant subset of identified articles or ‘test-list’ constructed at the scoping stage. The table contains prompts to the reviewers to record all relevant information necessary to address the synthesis question, plus any additional information required for critical appraisal (see below) and any contextual information that will be required when writing the final evidence synthesis report. As with the eligibility screening step, the pilot test should involve at least two reviewers per article, so that any inconsistencies can be identified and corrected. Any issues with data presentation should be noted at this point, so that they may inform synthesis planning. For example, Review Teams may find that data are not consistently presented in a suitable format and that they may need to contact original authors for missing or raw data. The finally agreed draft data coding or extraction table should then be provided when the evidence synthesis protocol is submitted (see Section 4). Data coding and extraction tables for Systematic Reviews are likely to be more detailed than Data coding tables for Systematic Maps, reflecting the different principles of these evidence synthesis methods (as explained in Section 2). Data coding in Systematic Reviews should take into account capture of information on potential reasons (effect modifiers) for heterogeneity in outcomes.
6.3 Assessing agreement between data coders/extractors
An assessment of agreement between members of the review team tasked with data extraction during pilot-testing can help to ensure that the process is reproducible and reliable as it is for screening (Frampton et al 2017). Ideally, data extraction should be piloted on a sample of relevant studies at the planning stage (see Section 3). However, data extraction outlined in the protocol may need to be modified following assessment and re-tested to improve the agreement between team members.
It is difficult to perform formal statistics on the repeatability of data extraction, but some attempt to verify repeatability should be made. Ideally a second reviewer should check all data extraction. If not possible then a second reviewer should at least check a random subset of the included studies to ensure that the a priori rules have been applied or the rationale of deviations explained. Randomly checking team members’ interpretation of data extraction in the protocol acts as a check on data hygiene and human error (e.g. misinterpretation of a standard error as a standard deviation). Where data extraction has limited repeatability it is desirable to maintain a record of exactly how the extraction was undertaken on a study by study basis. This maintains transparency and allows authors and other interested parties to examine the decisions made during the extraction process. Particular attention should be paid to the data used to generate effect sizes. For transparency, data extraction forms should be included in an appendix or supplementary material.
6.4 Data coding
Provided sufficient planning has been undertaken at the protocol stage, data coding should be a relatively straightforward task involving careful reading of the full text of each study. Variables or characteristics to be coded for each study should be included in a suitable spreadsheet prior to coding. Although the list of coded variables should have been discussed with stakeholders at the planning stage, there will usually be a need to refine definitions and discuss details of how each variable should be coded once the studies are read at full text. Decisions taken at this stage should be fully reported.
For Systematic Reviews, some of the variables coded will be potential effect modifiers that may cause heterogeneity in effect and therefore need special consideration in terms of how they are recorded so as to facilitate their inclusion in further analysis such as subgroup analysis and meta-regression (see Section 8). Some variables may be categorical whilst others will be continuous. In some cases, quantitative variables may need to be recorded as means and variances in the same way as effect sizes.
For Systematic Maps, some of the variables may be used to sort studies into subgroups for data visualisation. Potential methods of data visualisation should be fully considered in advance of data coding so that the necessary information is recorded. Table 6.1 shows an example of a coding sheet from a Systematic Map on human health impacts resulting from exposure to alien species in Europe (Bayliss et al 2017).
Table 6.1 Example of a coding sheet for a Systematic Map on human health impacts resulting from exposure to alien species in Europe (Bayliss et al 2017)

6.5 Data extraction
When adapting or designing a data extraction form, review authors should first consider how much information should be collected. Extracting too much information can lead to forms that are longer than original study reports and can be very wasteful of time. Extraction of too little information, or omission of key data, can lead to the need to return to study reports later in the review process.
Sensitivity analyses can be used to investigate the impact of extracting data in different ways when there is doubt about the optimum extraction method. When extracting data from quantitative studies, it is standard practice to extract the raw or summary data from included studies wherever possible, so a common statistic can be calculated for each study. The results of studies included in a review may take different numerical or statistical forms, which may involve transforming results into a common numerical or statistical measure if possible. In a review of effectiveness which incorporates meta-analysis these results would be pooled to provide a single estimate of effect size (see Section 8). It is important to extract data that reflect points of difference and any heterogeneous characteristics between studies that might affect data synthesis and interpretation of the findings. Whether statistical data synthesis can be performed will depend largely on the heterogeneity of the variables of interest across included studies.
Good practice for data extraction could involve the following steps, which improve transparency, repeatability and objectivity:
- Report the location of study data within each article and means of extraction if data are located within figures.
- Provide the pre-tested data extraction form.
- Data extraction by multiple reviewers using a subset of eligible studies and checking for human error/consistency.
- Include appendices of extracted information.
- Detail contact made with authors requesting study data where they are missing from relevant articles.
- Describe any pre-analysis calculations or data transformations (e.g. standard deviation calculation from standard error and sample size (e.g. Felton et al. 2010 and Smith et al. 2010), and calculation of effect sizes.
Table 6.2 shows and example of a data extraction table from a Systematic Review on the influence of a reduction of planktivorous and benthivorous fish on water quality in temperate eutrophic lakes (Bernes et al 2015)
Table 6.2 Data extraction table from Bernes et al (2015)
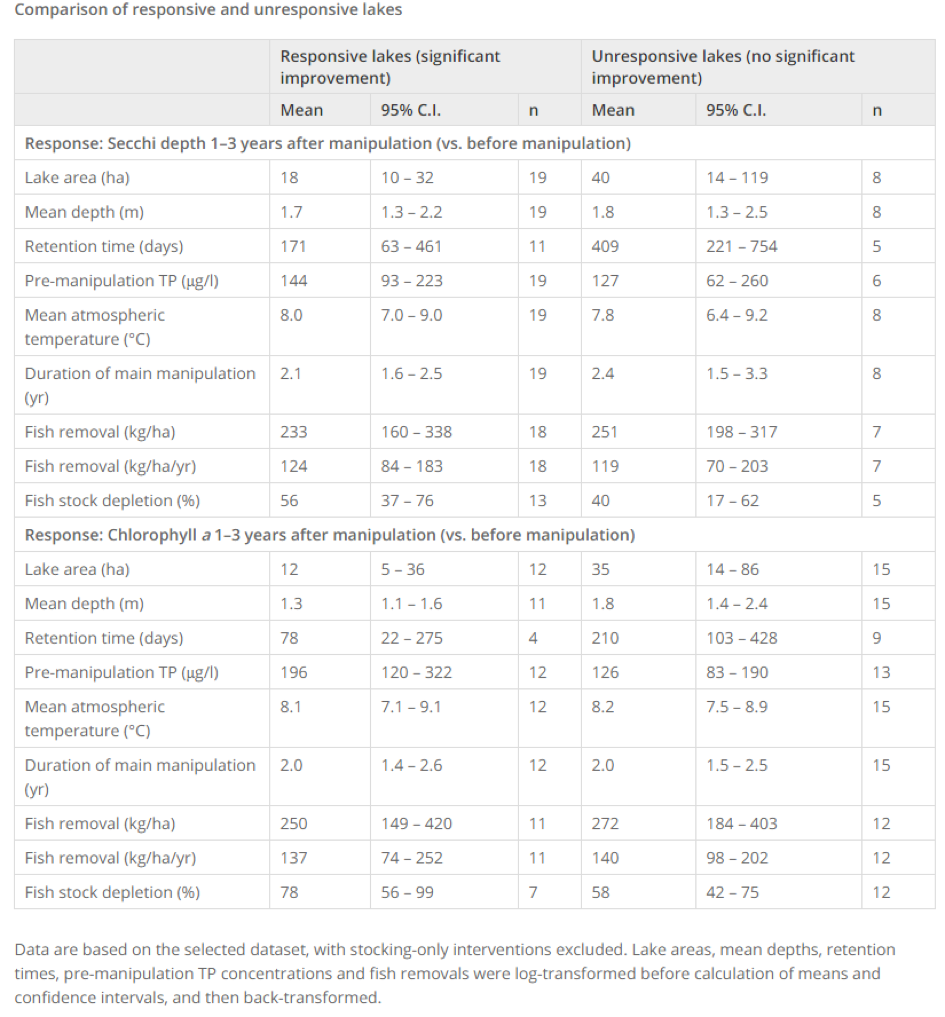
At this stage, it may be necessary to exclude studies that are seemingly relevant but do not present data in extractable format (e.g. if they do not report standard deviations for control and treatment group(s) or the information required to calculate the statistic). If possible, authors of such studies should be contacted and asked whether they can provide data in a suitable format. Contacting authors for data is not normal practice in environmental science and can be met with surprise and indignation, but it is important to develop the culture and expectation of data accessibility, particularly when the research was publicly funded.
In some cases, where the information required is not presented and cannot be obtained from authors, data can be converted into an appropriate form without problems. For example, it is relatively straightforward to substitute standard deviation for standard errors, confidence intervals, t-values, or a one-way F-ratio based on two groups (Lipsey & Wilson 2001, Deeks et al. 2005). Where missing data cannot be substituted, it can be imputed by various methods. Imputation is a generic term for filling in missing data with plausible values. These are commonly derived from average or standardised values (Deeks et al. 2005), but also from bootstrapped confidence limits (Gurevitch & Hedges 2001) or predicted values from regression models (Schafer 1997). Alternatively, data points can be deleted from some analyses, particularly where covariates of interest are missing. Such pragmatic imputation or case deletion should be accompanied by sensitivity analyses to assess its impact.
The impacts of imputation or case deletion can be serious when they comprise a high proportion of studies in an analysis. Case deletion can result in the discarding of large quantities of information and can introduce bias where incomplete data differ systematically from complete (Schafer 1997). Likewise, imputing average values or predicted values from regressions distorts covariance structure resulting in misleading p-values, standard errors and other measures of uncertainty (Schafer 1997). Where more than 10% of a data set is missing serious consideration should be given to these problems. More complex imputation techniques are available (see Schafer 1997) and should be employed in consultation with statisticians. If this is not possible, the results should be interpreted with great caution and only presented alongside the sensitivity analysis. Section 9 discusses data analysis in greater detail.
Continue to Section 7 – Critical appraisal of study validity